
I am a senior algorithm engineer at Alibaba Group, where I am a member of the prestigious T-Star Talent Program within the Taobao and Tmall Group (TTG). I earned my Ph.D. from the University of Science and Technology of China (USTC, advised by Dong Liu) and my Bachelor’s degree from Xi’an Jiaotong University (XJTU).
My research focuses on Multimedia AIGC, with specific interests in:
-
Post-training for Video Foundation Models.
-
Reinforcement Learning (RL) applications in Diffusion Models.
-
Video Completion and Synthesis.
I have published several papers in top-tier conferences and journals, including CVPR, ECCV, and TPAMI.
🔥 We are hiring! Our team is constantly looking for motivated interns. If you are interested in pushing the boundaries of generative AI, please reach out to me at: richu@mail.ustc.edu.cn.
🔥 News
- 2026.02: 🎉🎉 LocalDPO is accepted to CVPR 2026
- 2026.01: 🎉🎉 LaCon is accepted to TIP
- 2025.12: 🎉🎉 StableV2V is accepted to TCSVT
- 2025.08: 🎉🎉 DrimNeRF is accepted to TCSVT
- 2024.05: 🎉🎉 SketchRefiner is accepted to TMM
- 2024.01: 🎉🎉 FGT++ is accepted to TPAMI
- 2022.07: 🎉🎉 FGT is accepted to ECCV 2022
- 2022.02: 🎉🎉 ISVI is accepted to CVPR 2022
📝 Publications
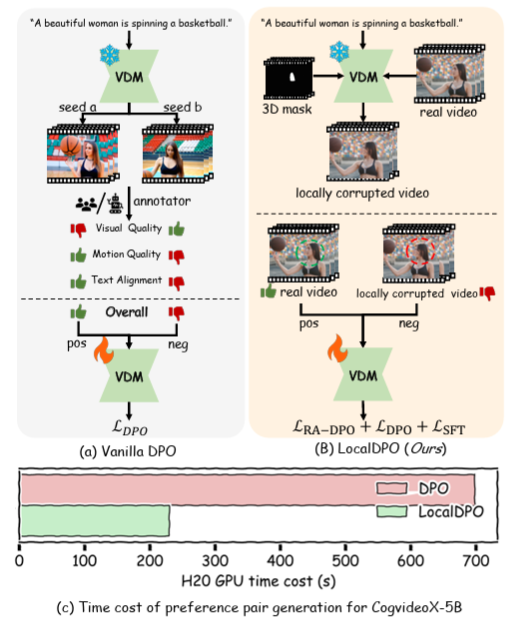
Zitong Huang*, Kaidong Zhang*, Yukang Ding, Chao Gao, Rui Ding, Ying Chen, Wangmeng Zuo (*equal contribution)
LocalDPO is an efficient post-training framework that aligns text-to-video models with human preferences by using an automated pipeline to create localized spatio-temporal preference pairs from real videos, enabling fine-grained region-aware optimization without the need for external critic models or multi-sample ranking.
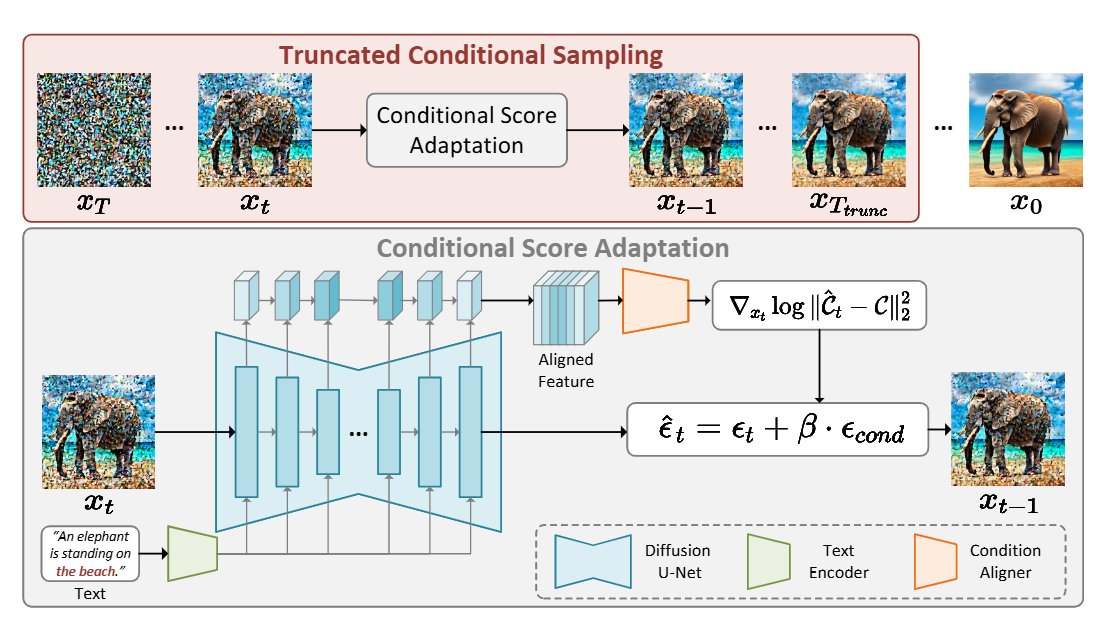
LaCon: Late-Constraint Diffusion for Steerable Guided Image Synthesis
Chang Liu, Rui Li, Kaidong Zhang, Xin Luo, Dong Liu
LaCon is a flexible and efficient “late-constraint” paradigm that achieves steerable image synthesis by aligning external conditions with the internal features of pre-trained diffusion models to guide the sampling process without requiring extra modules or heavy parameter optimization.

StableV2V: Stablizing Shape Consistency in Video-to-Video Editing
Chang Liu, Rui Li, Kaidong Zhang, Yunwei Lan, Dong Liu
StableV2V presents a novel paradigm to perform video editing in a shape-consistent manner, especially handling the editing scenarios when user prompts cause significant shape changes to the edited contents.
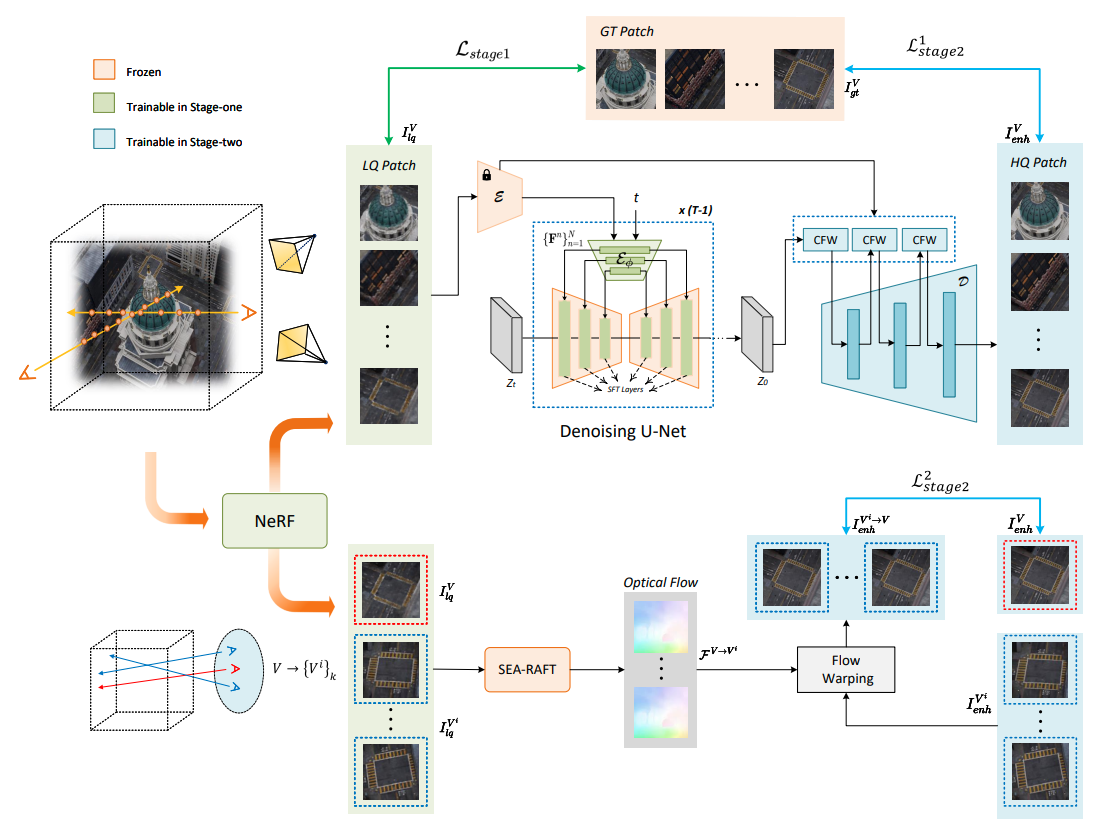
Drim-NeRF: Diffusion-Based Restoration for Improving Neural Radiance Fields
Ganlin Yang, Kaidong Zhang, Jingjing Fu, Dong Liu
Drim-NeRF is a diffusion-based, backbone-agnostic restoration method that treats NeRF artifacts as a specific degradation model and utilizes optical flow warping along with feature-wrapping in the VAE decoder to produce high-fidelity, multi-view consistent enhancements for complex scenes.
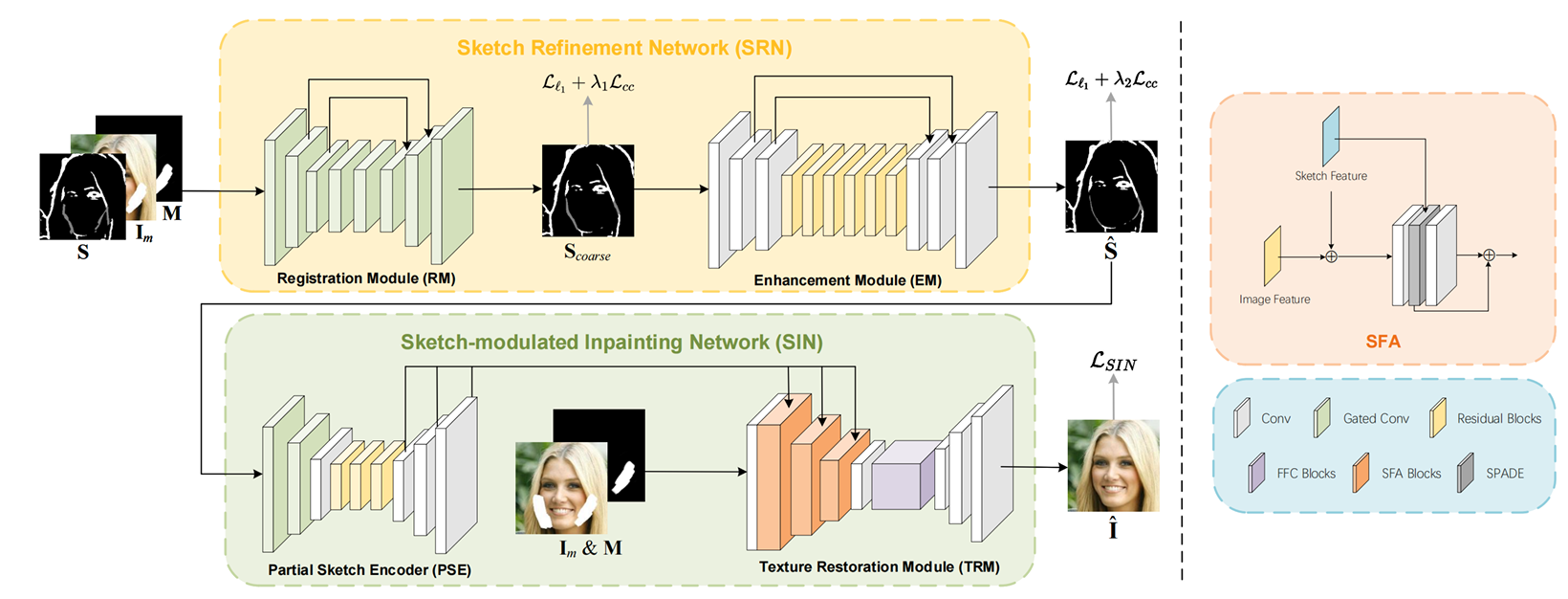
Toward interactive image inpainting via robust sketch refinement
Chang Liu, Shunxin Xu, Jialun Peng, Kaidong Zhang, Dong Liu
This paper explores the guidance of sketch in image inpainting. It seperates the completion of sketch and image and designs two specialized networks for excellent image inpainting performance.
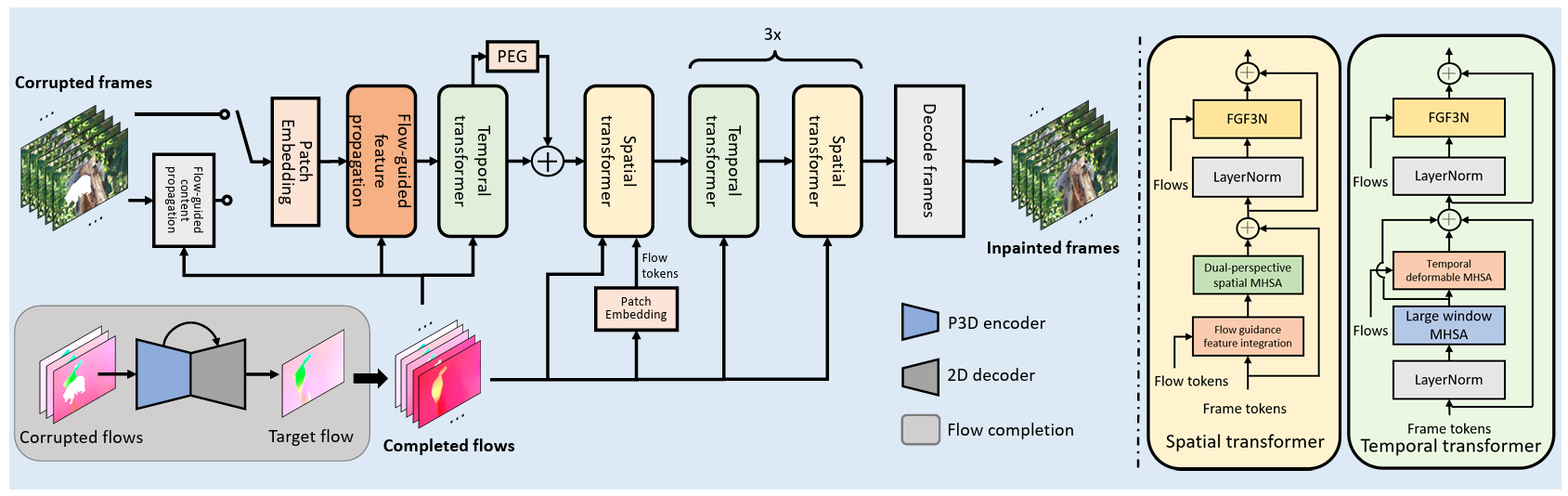
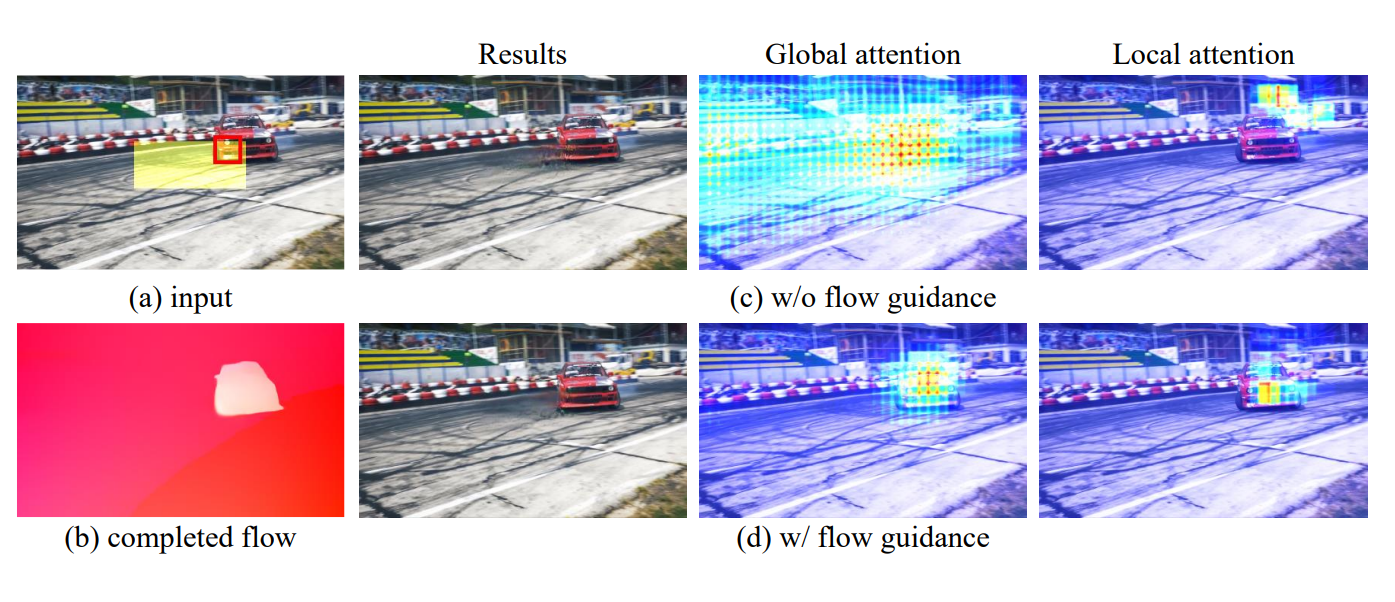
Exploiting Optical Flow Guidance for Transformer-Based Video Inpainting
Kaidong Zhang, Jialun Peng, Jingjing Fu, Dong Liu
This paper investigates how to use the power of optical flows to guide the video inpainting transformer systematically. It reaches SOTA video inpainting performance against all of the previous counterparts.
Flow-Guided Transformer for Video Inpainting
Kaidong Zhang, Jingjing Fu, Dong Liu
FGT is the first video inpainting framework that utilizes the optical flows to influence attention calculation in transfomer for video inpainting with higher fidelity.

Inertia-guided flow completion and style fusion for video inpainting
Kaidong Zhang, Jingjing Fu, Dong Liu
ISVI is a novel flow-guided video inpainting system that integrates inertia into flow completion and adopts additional style correction to produce completed videos with high fidelity.
📝 Arxiv Preprints
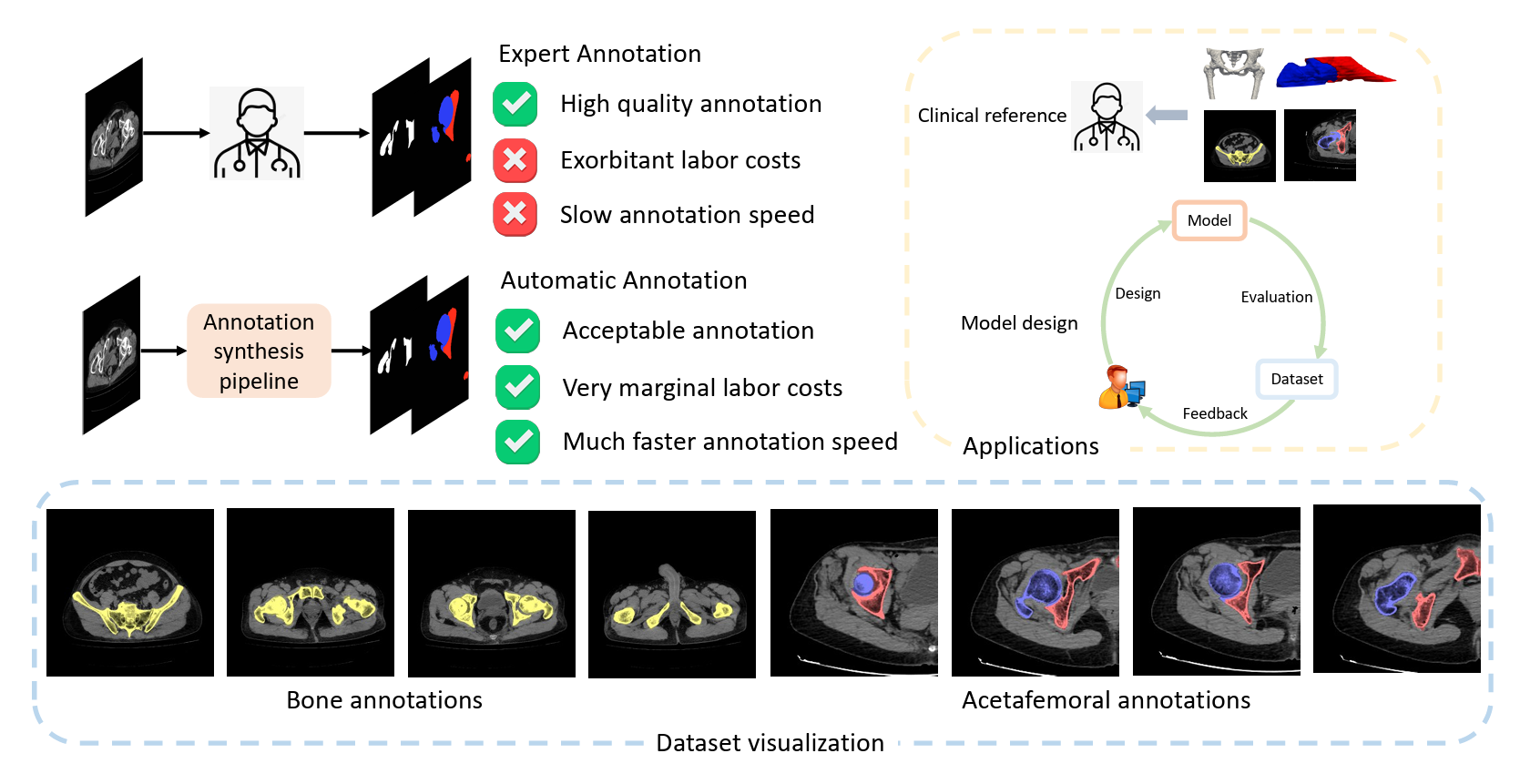
A Dataset for Deep Learning-based Bone Structure Analyses in Total Hip Arthroplasty
Kaidong Zhang, Ziyang Gan, Dong Liu, Xifu Shang
The researchers propose an efficient bone structure annotation pipeline that combines non-learning-based segmentation (using graph-cut and gradient-based algorithms) with active-learning-based refinement to create a large-scale, high-quality THA dataset with minimal manual labeling.

Customized segment anything model for medical image segmentation
Kaidong Zhang, Dong Liu
SAMed is the seminal work that utilizes Segment Anything Model (SAM) in multi-organ segmentation. It achieves remarkable performance and demonstrates the feasibility of SAM in medical usage.
🎖 Honors and Awards
- 2022.12 Invited speaker in Youth PhD Talk-ECCV 2022, hosted by AITime.
- 2022.01 MSRA Star of Tomorrow Excellent Internship Award
- 2020.01 2nd place (runner up) in AI+4K HDR track of the first National Artificial Intelligence Competition (CNY 500K)
📖 Educations
- 2019.09 - 2024.06, Ph.D. Electronics and Information Engineering, University of Science and Technology of China, China.
- 2015.09 - 2019.06, B.S. Electronics and Information Engineering, Xi’an Jiaotong University, China.
💬 Invited Talks
- 2022.10, Flow-Guided Transformer for Video Inpainting | [video]
💻 Internships
- 2020.08 - 2022.02, Microsoft research Asia (MSRA), China, advised by Jingjing Fu.